
机器学习笔记Ⅵ-GAN理论2
参考:https://www.bilibili.com/video/BV1Wv411h7kN?p=42&spm_id_from=pageDriver
生成器效能评估与条件生成
在上一篇笔记中,我们学习了使用wasserstein distance改进divergance计算方法,但直到这一步,gan网络的训练仍会出现困难,因为gan网络包含两个即相互独立又相互促进的生成器和鉴别器,只有每次生成器和鉴别器都有进步,正向的促进循环才能继续下去。
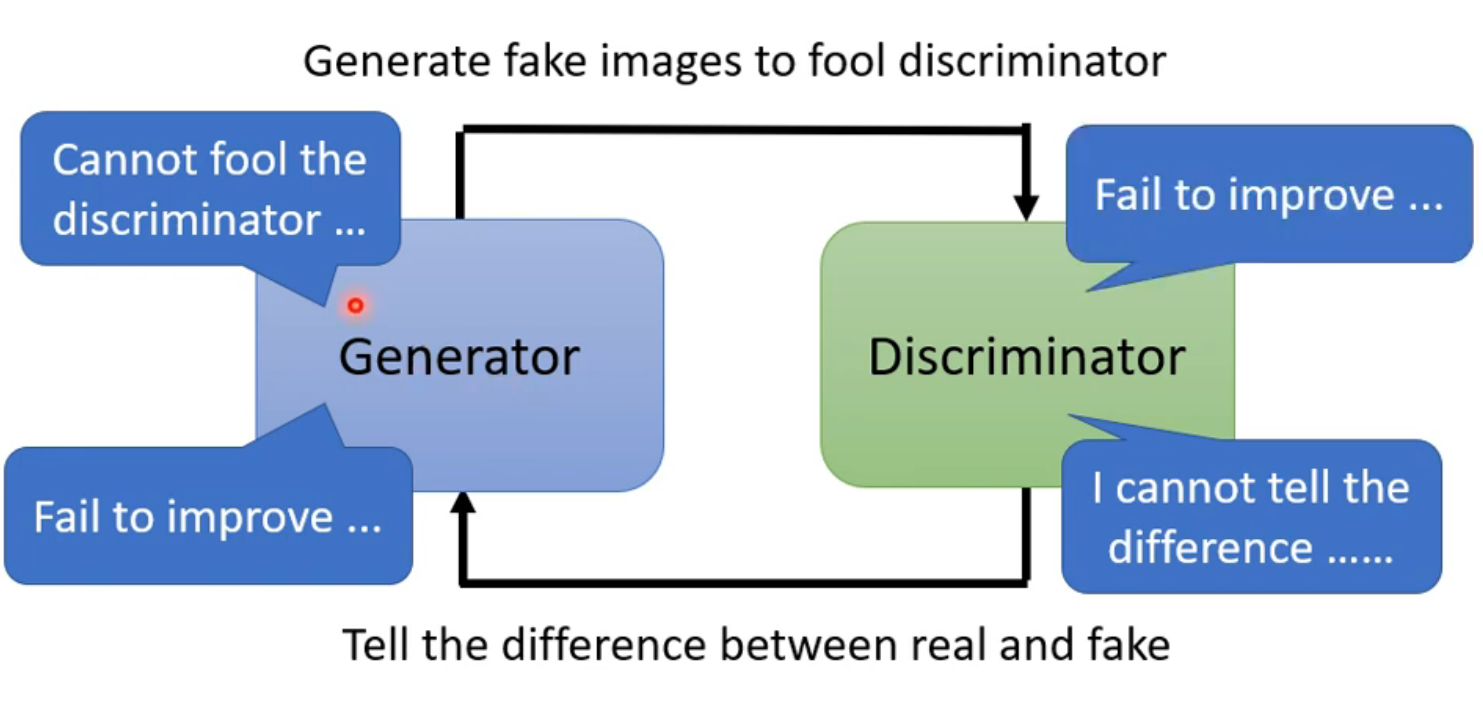
gan训练技巧参考:

除GAN以外的其他机器学习模型:VAE,FLOW,这两种模型效果不如GAN

其他方法:supervised learning:假设要使用generator生成二次元图片,我们首先给样本一堆满足某一分布的随机生成的向量,每一个向量对应一个真实图片,并把随机向量当作输入,图片当作输出,来训练网络。可参考下图论文:

生成器评估方法
quality评估:对于影像生成器,可以将产生的结果放到一个影像分类器里,如果输出的结果分布越集中(分类器对图片的结果很确定),说明生成效果越好。

但如果仅评价quality,会出现多样性问题,包括mode collapse和mode dropping
mode collapse:训练到最后生成器的输出很单一
mode dropping:生成器输出有多样性,但离真实数据还有差距

多样性问题的解决:
将生成器生成的图片放到分类器中进行分类,并对每一张图片分类结果按class求平均,如果每一个class平均分数没有太大的差别,说明生成器生成图片的多样性是够的。(注意:quality评估和diversity评估都用到分类器,但quality只看一张图片分类结果是否集中,而diversity看许多生成的图片在分类结果上是否分散)
多样性差的生成器:

多样性好的生成器

Inception Score(IS)
将两种评价结合就得到了Inception Score(IS),如果quality分数高,diversity分数也高,那么IS的分数才会高。IS并不适用于所有GAN评估,如在二次元人脸生成中,即使生成的图片中存在多样性,分类器会把它们都认成人脸,很难分辨。
Frechet Inception Distance(FID)
FID与IS不同的是,FID将真实数据和分类器生成数据同时丢进分类器,在比较分类器输出是否有差异时选择softmax上一层隐藏层的输出来判断。将真实数据和生成器生成的数据都在分类器进行分类,取隐藏层输入向量,假设真实图片和生成器生成都是高斯分布的,计算二者样本的隐藏层输入向量之间的弗朗明歇距离(Frechet distance),弗朗明歇距离越小说明GAN越好。
采用高斯分布会有一定的问题,如果要得到数据真实的分布需要大量的样本,运算量比较大

其他GAN生成器评估方式:https://arxiv.org/abs/1802.03446
条件生成
之前的内容提到的生成器都是仅输入一个特定的分布样本,条件生成是指在输入某个简单分布的同时再加上控制条件x,如文字对图片的生成。
在使用条件生成器时,鉴别器也需要做出调整,鉴别器需要把成对的(条件,值)数据当作输入,如果条件和数据成对,输出1。

cycle GAN
试想有一种情况,我们的输入和输出没办法对应,比如将真实的人脸转变成二次元人脸,我们的样本只有一堆真实的人脸的图片和一堆二次元人脸图片,在这种情况下,可以把GAN中的简单分布换成我们的输入,即把输入当成时一种分布,从输入的分布得到输出的分布。

仅仅把简单的分布换成我们的输入,生成器可能会产生输出,但这个输出未必与输入是有关联的。Cycle domain可以解决这个问题。cycle domain在GAN中多加了一个生成器,要完成的任务是输入经过生成器变成输出,输出再经过一个生成器变回输入,使最终的输出与输入越接近越好。这样可以强制让生成器的输入输出有一定的联系。

